Nature:为高维度医学成像设计可临床转化的人工(4)
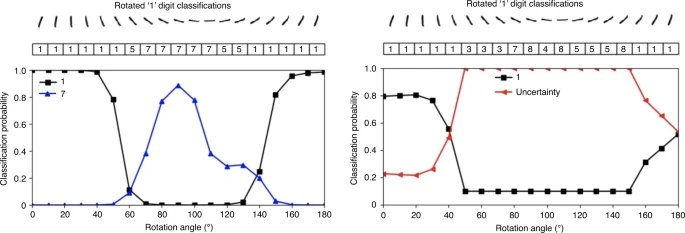
图 2:量化机器学习输出中的不确定性。
正如 Sensoy 等人所描述的那样,即使在不正确的情况下,使用标准方法训练的机器学习模型也可以非常自信。左图:当一个数字被旋转180°时,系统自信地分配了一个从 "1 "到 "7 "的标签。右图:然而,用考虑分类不确定性的方法,系统会分配一个不确定性分数,可以帮助提醒临床医生潜在的错误预测。
然而,从可操作的角度来看,时间-事件预测可能存在问题。在肺癌筛查的假设示例中,胸部计算机断层扫描中的可疑结节可能会产生一个预测,即在有或没有适当的治疗干预的情况下的中位生存率。对临床医生来说,了解机器学习系统对个体病人的预测的有多大的把握可能是很有意思的。当对一项任务没有把握时,人类往往会谨慎行事。机器学习系统也反映了这一点,其中输出是 0 到 1 范围内的“类别概率”或“正确的可能性”。然而,目前文献中描述的大多数医学影像机器学习系统,当提供给模型的输入数据超出分布范围时,缺乏说 "我不知道 "的隐含能力。例如,即使输入图像是猫的图像,训练用于从计算机断层扫描(例如)预测肺炎的分类器在设计上也被强制提供输出(肺炎或非肺炎)。
在他们关于深度学习中的不确定性量化的论文中,Sensoy等人用一系列的损失函数来解决这些问题,这些损失函数分配了一个 "不确定性分数",以此来避免错误的、但有把握的预测。在项目的转化阶段,当人工智能系统被部署在与人类用户一起工作的环境中时,不确定性量化的好处就出现了。信心度量是AlphaFold2的一个关键因素,该蛋白质折叠机器学习系统在第14届蛋白质结构预测关键评估(CASP14)挑战中取得了无与伦比的准确性,给DeepMind研究团队提供了一种方法来衡量他们应该对正在生成的预测给予多大的信任。许多不确定性量化方法的实现都是在许可的情况下进行的,并且与常用的机器学习框架兼容。纳入不确定性量化可能有助于提高高风险的医学成像机器学习系统的可解释性和可靠性,并减少自动化偏差的可能性。
除了量化某些机器学习系统的预测效果外,对于构建这些系统的工程师和使用它们的临床医生来说,他们更感兴趣的是了解这些机器学习系统是如何得出结论的。显著性图和类激活图实际上仍然是解释机器学习算法如何进行预测的标准。
Adebayo等人最近的研究表明,仅仅依靠显著性图的视觉外观可能会产生误导,即使乍一看它们与背景相关。在一系列广泛的测试中,他们发现,许多流行的生成事后显著性图的方法并没有从模型权重中获得真正的意义,而是与 "边缘检测器"(简单映射像素强度之间的尖锐过渡区域的算法)没有区别。此外,即使这些可视化方法奏效,除了机器学习算法正在寻找的 "位置 "之外,也几乎无法破译。在很多示例中,无论是正确还是错误的显著性图看起来几乎是一样的。当 "患病 "状态和 "正常 "状态之间的差异需要关注图像或视频的同一区域时,这些缺点就更加明显了。
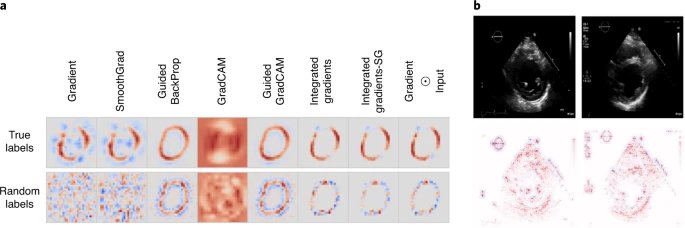
图3:事后模型解释的误导性。
a, Adebayo等人用MNIST数据集的真实标签训练的模型(上)和随机噪声训练的模型(下)进行的实验。当通过大多数可视化方法进行评估时,在随机噪声上训练的模型仍然产生圆形形状。b,超声心动图视图平面的检测:错误的分类(左上)和正确的分类(右上)都产生类似的显著性图(下)。
临床医生应该注意,仅靠热图不足以解释 AI 系统的功能。在尝试用如上图所示的可视化方法来识别故障模式时,必须谨慎。一个更精细的方法可能涉及到连续遮挡测试,即在有意掩盖临床医生用来进行诊断或预测的区域后,评估图像的性能。这个想法非常直观:在已知对诊断某种疾病很重要的区域被遮蔽的图像上运行算法,例如,在试图诊断心力衰竭时遮蔽左心室,应该可以看到性能的急剧下降。
这有助于确认人工智能系统正在关注相关领域。特别是在高维医学成像研究的背景下,激活图可能为视频类成像研究的某些时间阶段的相对重要性提供独特的见解。例如,某些疾病可能在心脏收缩时表现出病理特征,而对于其他疾病可能需要人们关注心脏放松时的情况。通常这样的实验可能表明,机器学习系统从临床医生传统上不会使用的图像区域中识别出潜在的信息特征。除了收集关于这些机器学习系统如何产生其输出的信息外,严格的可视化实验可能提供一个独特的机会,可以从被评估的机器学习系统中学习生物学的见解。
文章来源:《中国临床解剖学杂志》 网址: http://www.zglcjpxzz.cn/zonghexinwen/2022/0121/535.html